Authors:
Published:

Today we’re releasing WARC-GPT: an open-source, highly-customizable Retrieval Augmented Generation tool the web archiving community can use to explore the intersection between web archiving and AI. WARC-GPT allows for creating custom chatbots that use a set of web archive files as their knowledge base, letting users explore collections through conversation.
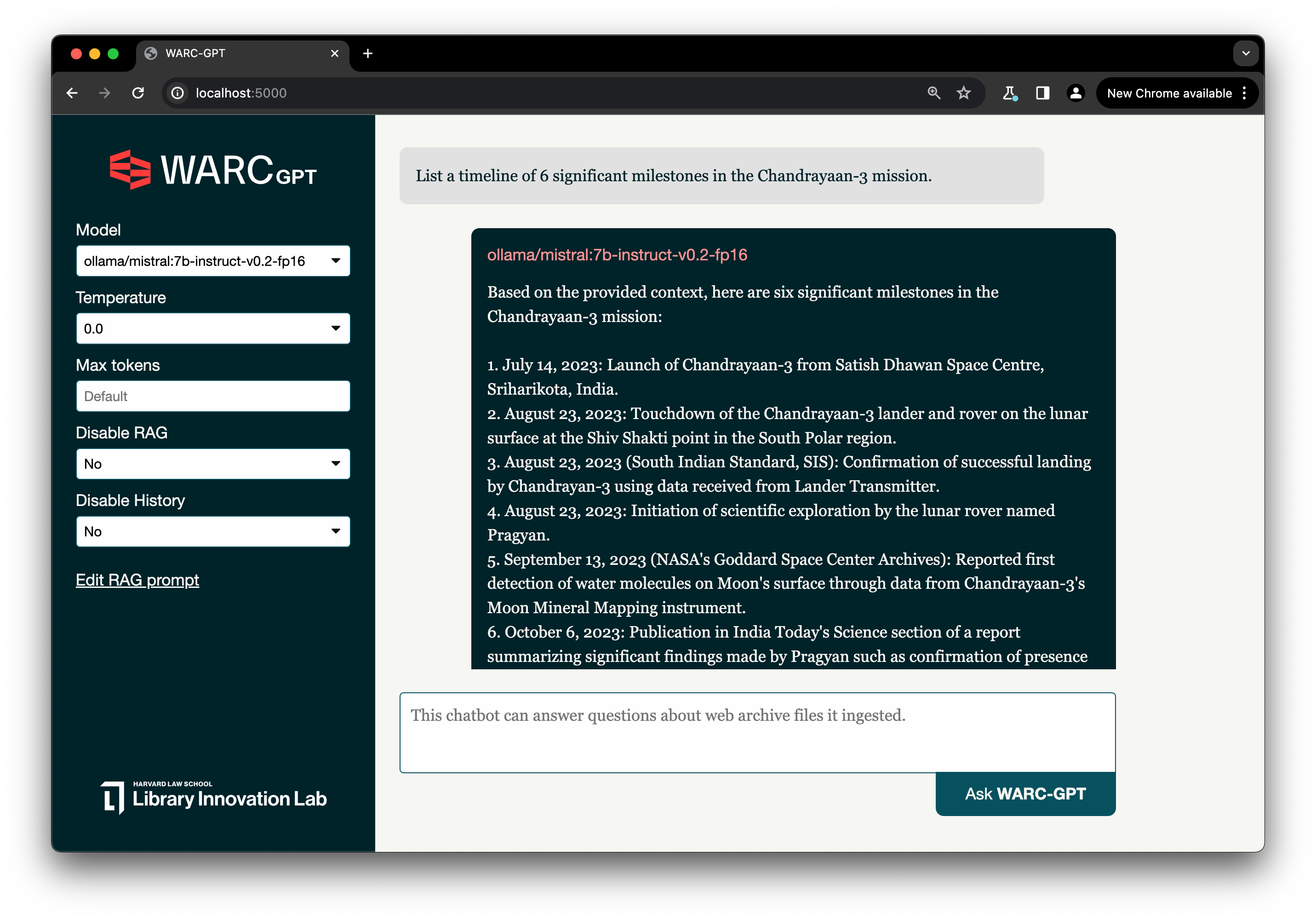
Using WARC-GPT, you can ask specific questions in natural language against a collection of WARC files. Rather than relying on keyword searches and metadata filters to sort through search results, WARC-GPT provides a new starting point for search using multi-document full-text search with summarization to explore the contents of web archives. WARC-GPT lists the sources used to generate the response and relevant text excerpts, which you can use to verify the information provided and identify points of interest within a collection of web archives.
This project is part of our ongoing series exploring how artificial intelligence changes our relationship to knowledge. The release of this experimental software will help us understand whether and how AI can help access and uncover web archives’ contents. Of course, this is simply a prototype – see our disclaimer in the repo.
If you want to run WARC-GPT yourself, head over to Github for installation instructions. If you are a library professional, researcher or tinkerer who wants to understand Retrieval Augmented Generation and how it can apply to specialized digital archives like web archives, read on.
Background
At the Library Innovation Lab, we build tools, explore new technologies, seed communities, and conduct research. One goal of our work is to bring library principles to cutting-edge technologies. Another is to bolster the ability of LAM practitioners to engage with these technologies as informed participants. It is under this framework that we have started working on WARC-GPT, as part of our explorations of the intersection of AI and web archiving.
The Large Language Models (LLMs) powering chatbots since the first release of ChatGPT are trained on large-scale, general-purpose datasets, which help them learn about language and the world. They are able, to a certain extent, to answer questions and perform tasks in part because they have been exposed to a wide variety of data in their training. There are limitations to this approach: a general dataset may not have reliable domain-specific information to reach for, or not have retained said information in its weights and biases. This may lead the model to “hallucinate” an answer, or deliver unhelpful responses for a person with existing knowledge of a topic. Additionally, since these models are pre-trained, there will be a cutoff date for their knowledge. Techniques for building atop the model and providing additional data to the model at inference time can help ground the knowledge of LLMs. Retrieval Augmented Generation (RAG) techniques are used to do just that, layering additional data for a model to use on top of its general knowledge. RAG does this by slightly complicating the usual prompt-response pairs of LLM-user interaction. A user’s prompt might first be run through a database maintained by someone other than the operator of the LLM, with the results then passed back as part of an augmented prompt containing both the user’s original query and the results from that immediate database search.
We therefore asked, would a RAG tool be useful in the context of a web archive collection?
WARC-GPT allows users to ingest and translate a collection of WARC files into a RAG setup that can be used with a variety of LLMs - essentially allowing archivists and researchers to use a chatbot that has knowledge of their collections. WARC-GPT is especially helpful for exploring private collections of WARCs or those that were not part of the training data for an LLM. Although LLMs are typically trained on data from sources like Common Crawl, an open repository of web crawl data that consists of over 250 billion pages, it is not possible to verify what data has been included. Grounding the knowledge of an LLM with a collection of WARCs provides relevant contextual information that is especially helpful for specific or specialized set of queries within a particular domain.
How does WARC-GPT work?
WARC-GPT is a Retrieval Augmented Generation pipeline. It allows for the creation of a knowledge base out of a set of documents – in that case WARC files – which is later used to help answer questions posed to a Large Language Model (LLM) of the user’s choosing.
That knowledge base is populated ahead of time, using WARC-GPT’s ingest command:
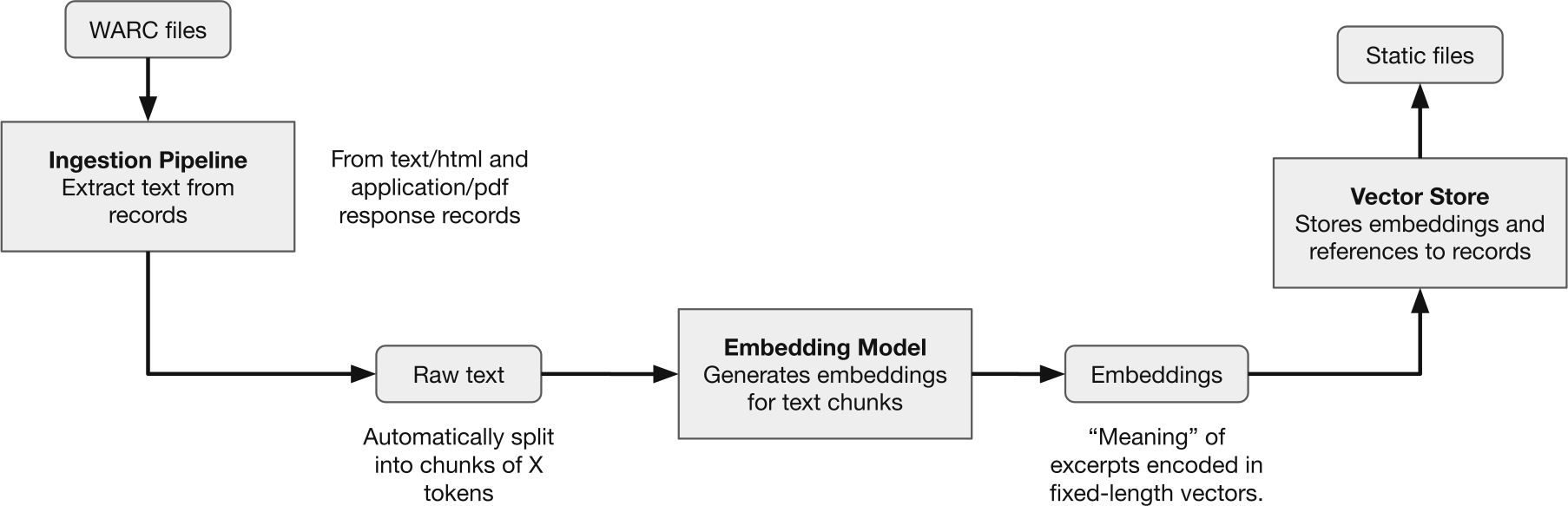
For each WARC file the pipeline can read, the program:
- Eliminates WARC records that are not HTTP 2XX responses of content-type
text/htmlorapplication/pdfcontaining retrievable text. - Extracts text from eligible WARC records.
- Splits the extracted text into chunks.
- Generates embeddings for each chunk using a sentence similarity model.
In this context, an embedding is a high-dimensional vector – a fixed-length series of values – which represents the “meaning” of the chunk of text. Embeddings are core to LLMs. In text generation models, they are used to predict what word should come next in a sentence. In sentence similarity models, they are used to evaluate how close in “meaning” two chunks of text are. - Stores embeddings alongside WARC-specific metadata in a collection-specific vector store.
At the end of that process, WARC-GPT has generated a database of embeddings which can be used to perform vector-based asymmetric semantic search. Since the vectors represent some aspects of the “meaning” of a given piece of text, vectors resulting from the encoding of pieces of text that are semantically similar will be close in value. This property allows for matching questions and document excerpts together using a distance function such as cosine similarity to group vectors of related meaning.
The following plot visualizes, in 2 dimensions, how that spatial question to text-excerpt matching works.
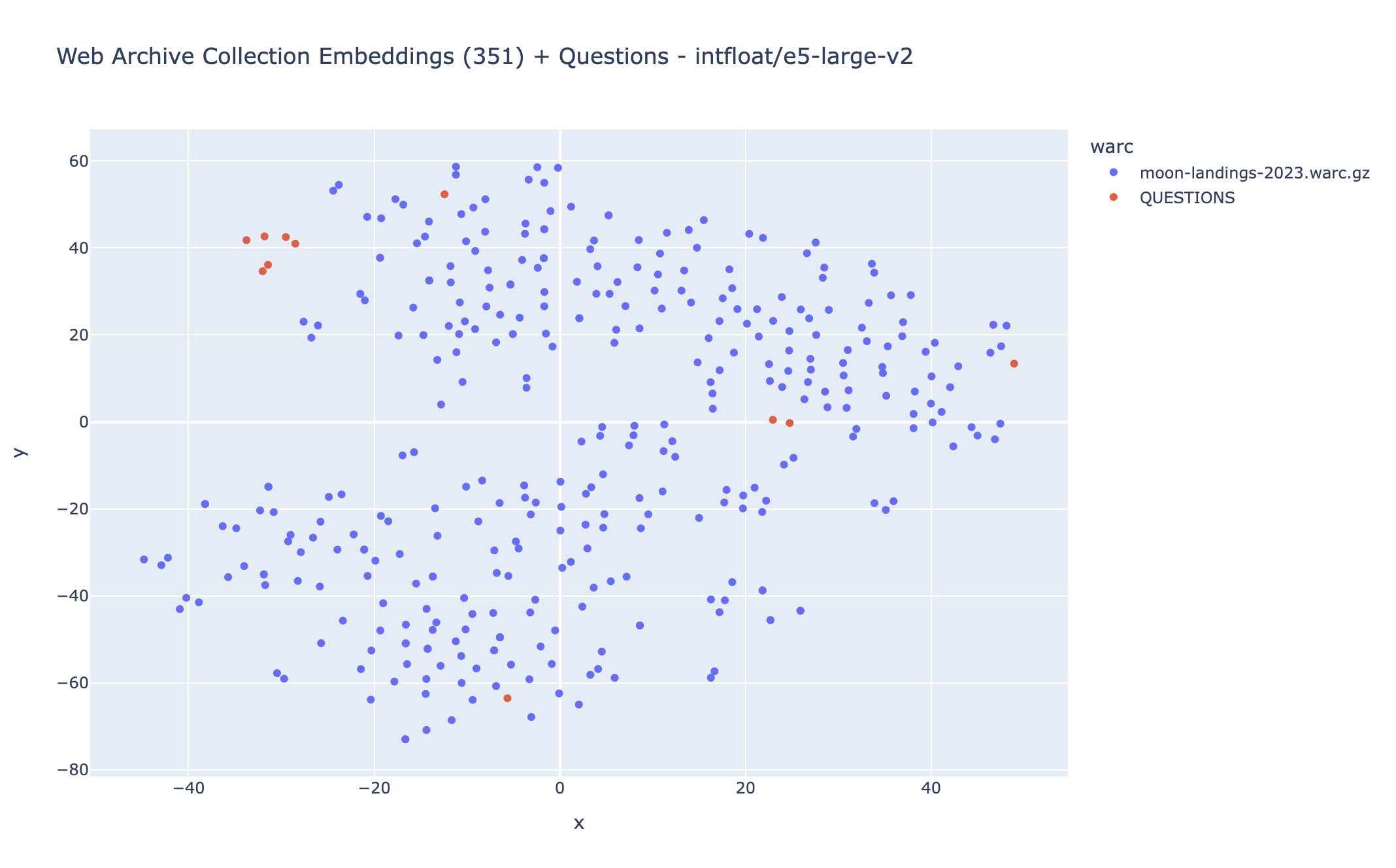
Dots in blue represent embeddings for text chunks out of WARC records, dots in red represent embedding for questions we asked.
Generated using WARC-GPT’s
visualize command.
WARC-GPT uses intfloat/e5-large-v2 as its default embedding model, which is a fairly large embedding model optimized for asymmetric semantic search which captures the meaning of sentences or paragraphs into 1024-dimensional vectors. That default model can be replaced with any SentenceTransformers-compatible model directly from WARC-GPT’s configuration file.
That knowledge base is then used by WARC-GPT’s REST API and web UI to help answer questions about the WARCs it has ingested:
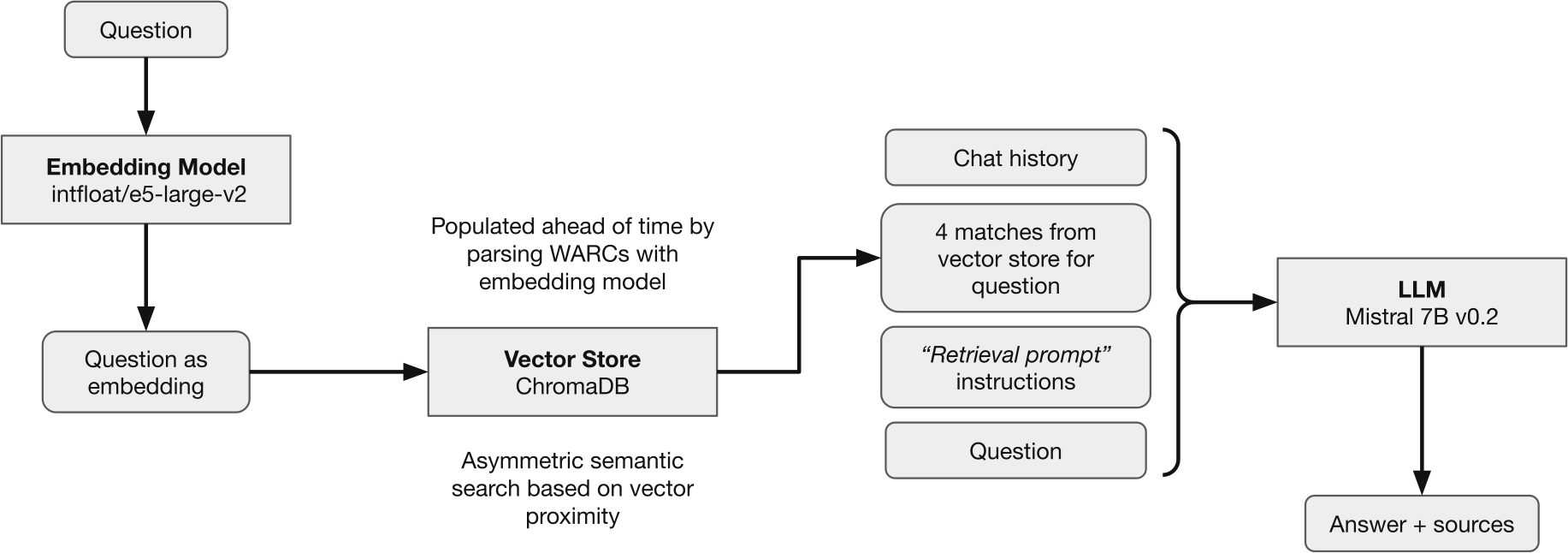
To answer questions, WARC-GPT processes questions using common RAG techniques which involve:
- Pulling from the vector store relevant text excerpts to the question that was asked.
The question is encoded using the same embedding model that was used to generate the knowledge base. The search process therefore consists in pulling the nearest neighbors of that question vector. - Coalescing the chat history, matches from the vector store, and question into a “retrieval prompt”.
This prompt contains instructions which help the LLM “understand” the provided context and the task at hand. - Sending the coalesced prompt to the LLM and returning the response to the user, along with the sources that were used to generate it.
WARC-GPT was designed with both high customizability and transportability in mind. Settings, models and prompts are meant to be interchanged and experimented with, and this is something we’ve tried to facilitate, to the extent that it did not interfere with the ability to run this software locally. By default, WARC-GPT will try to use Ollama as its inference server, which allows for running the entirety of the pipeline locally against open-source models, but it can also interact with closed-source LLM APIs such as Open AI or Anthropic, if API keys are provided in its configuration file.
Why use Retrieval Augmented Generation (RAG) to explore WARCs?
RAG techniques are generally deployed when the knowledge stored within an LLM’s internal weights isn’t sufficient for a particular application. They are, for example, used as a way to help LLMs “hallucinate” less by feeding domain-specific, contextual information into prompts in order to ground their responses. These techniques are also used to allow LLMs to go beyond their knowledge cutoff by giving them access to information created after they were originally trained. Finally, since LLMs tend to excel at summarization tasks, asking them to summarize and filter disparate pieces of context retrieved in a RAG setup can sometimes be used as a way to explore and make sense of a dataset using natural language.
Our hypothesis is that these same techniques can be used to learn about the contents of web archives, allowing us to ask questions in natural language against a set of WARC files as a way to explore voluminous, and sometimes under-cataloged archived web content. In a sense, RAG applied to web archives can be seen as an alternative search method: it is not meant to replace keyword and filter-based search, but instead to complement it, providing a different starting point for scholarly inquiry and potentially expanding access to otherwise hard-to-reach information.
This new mode of access comes with important trade-offs when compared with “traditional” search, the first being variability, which affects every single aspect of RAG pipelines.
- It starts with the creation of the knowledge base: the choice of the embedding model, distance function and ingestion method can have a massive impact on the performance of the context retrieval mechanism.
- It continues with prompting: variations in the retrieval prompt or the question itself might yield very different results.
- It ends with the choice of the text-generation model and its settings: different models behave differently, and settings such as temperature greatly affect how a given model interprets and responds to provided context.
More importantly, RAG sometimes sits at a strange place when it comes to reconstituting information. LLMs know about the world – to the extent that their weights and biases map out to the reality the datasets they were trained on describe – and it is sometimes difficult to distinguish, in a given response, what comes from the model’s own “knowledge,” as opposed to what it got from the sources it was given through RAG, even when those are listed separately.
Finally, there are as many flavors of RAG as there are RAG implementations available. The one WARC-GPT currently focuses on is not well suited for exploring and comparing multiple versions of a given page archived repeatedly over time or for performing large-scale analysis of web archives metadata, but is instead geared towards a form of augmented, multi-document full-text search with summarization, which can be useful to surface information contained in the archived documents themselves.
Putting WARC-GPT to the test
In order to test this first version of WARC-GPT and investigate how RAG techniques may help explore web archive collections, we assembled a small thematic collection of 78 URLs related to the lunar landing missions of India and Russia in 2023. Our goal here was mainly to ensure that WARC-GPT behaves as designed.
This topic appeared to be well suited for that experiment:
- Most models know of the lunar missions we wanted to ask about to a certain extent, but are unaware of crucial recent developments. For example Mistral 7B v0.2 Instruct, the model we chose to test against, knows “out of the box” about India’s Chandrayaan 3 mission, but only as a scheduled mission - as it was trained and released before the mission was completed.
- The scope and breadth of the collection is both specific and diverse: we curated news articles, encyclopedia pages and opinion pieces related to the crash of Russia’s Luna 25 mission and the success of India’s Chandrayaan 3 mission. This allowed us to design a set of questions focusing not only on the specifics of both missions, but also on the connection between the two.
The experiment we conducted consisted in running WARC-GPT’s default configuration against Mistral 7B at temperature 0.0 on a set of 10 questions in a zero-shot prompting scenario, with and without RAG, and to analyze the resulting output using the following criteria, inspired by the work of Gienapp et al.:
- Coherence: manner in which the response is structured and presents both logical and stylistic coherence.
- Coverage: extent to which the presented information is pertinent to the user’s information need, both in terms of breadth and depth.
- Consistency: whether the response is free of contradictions and reflects the information the system was provided as context.
- Correctness: whether the response provided is factually correct and reliable, free of factual errors and within the scope of the user’s information needs.
- Clarity: both in terms of language and content.
- Context relevance: Was the context added to the prompt as a result of vector-search on the knowledge base yield relevant results.
- Adherence to context: Whether (and how) the response made use of and / or reference to the provided context.
- Other response quality metrics: Whether the provided response contains hedging language or hallucinations.
We chose Mistral 7B as our text-generation model of reference because it can realistically be run on consumer hardware, and because we were able to identify the limitations of its knowledge on the topic we chose to explore. Furthermore, its context window (the amount of word-chunks it could process at once) was large enough to handle the context we are pulling from the vector store with each request – specifically: 4 text excerpts of up to 512 tokens each.
While we acknowledge the limitations of the small sample size utilized in this series of tests, the results are nevertheless an encouraging indication that the tool behaves as expected and is suitable for experimentation. Further research with larger and more diverse collections will be necessary to validate the robustness and generalizability of these initial observations.
On this set of questions and with this specific setup, we’ve identified that WARC-GPT was able to provide compelling answers in most cases, and made appropriate use of the provided sources, most of which were relevant. We’ve observed that not only did RAG extend the model’s knowledge beyond its cut-off, but it also helped identify resources relevant to the question at hand in the web archives collection.
Compare, for example, the difference in responses to the question “Did the Chandrayaan-3 spacecraft come back to Earth?”
Without RAG: No, the Chandrayaan-3 spacecraft did not come back to Earth. It was India’s third lunar exploration mission, designed to soft land a rover named Pragyan in the Moon’s South Polar region. Unfortunately, the landing was unsuccessful and the spacecraft crashed on the lunar surface. The primary objective of the mission was to extend the exploration of the moon by studying its mineralogical resources and help India establish a sustainable lunar presence.
With RAG: Yes, according to the context provided, the Chandrayaan-3 propulsion module, which was used to power the lunar lander during its journey to the moon, has returned to Earth’s orbit. The Indian Space Research Organization (ISRO) confirmed this development on Monday. The goal of bringing the module back to Earth is to test ISRO’s capabilities for future missions that may involve returning lunar samples to Earth.
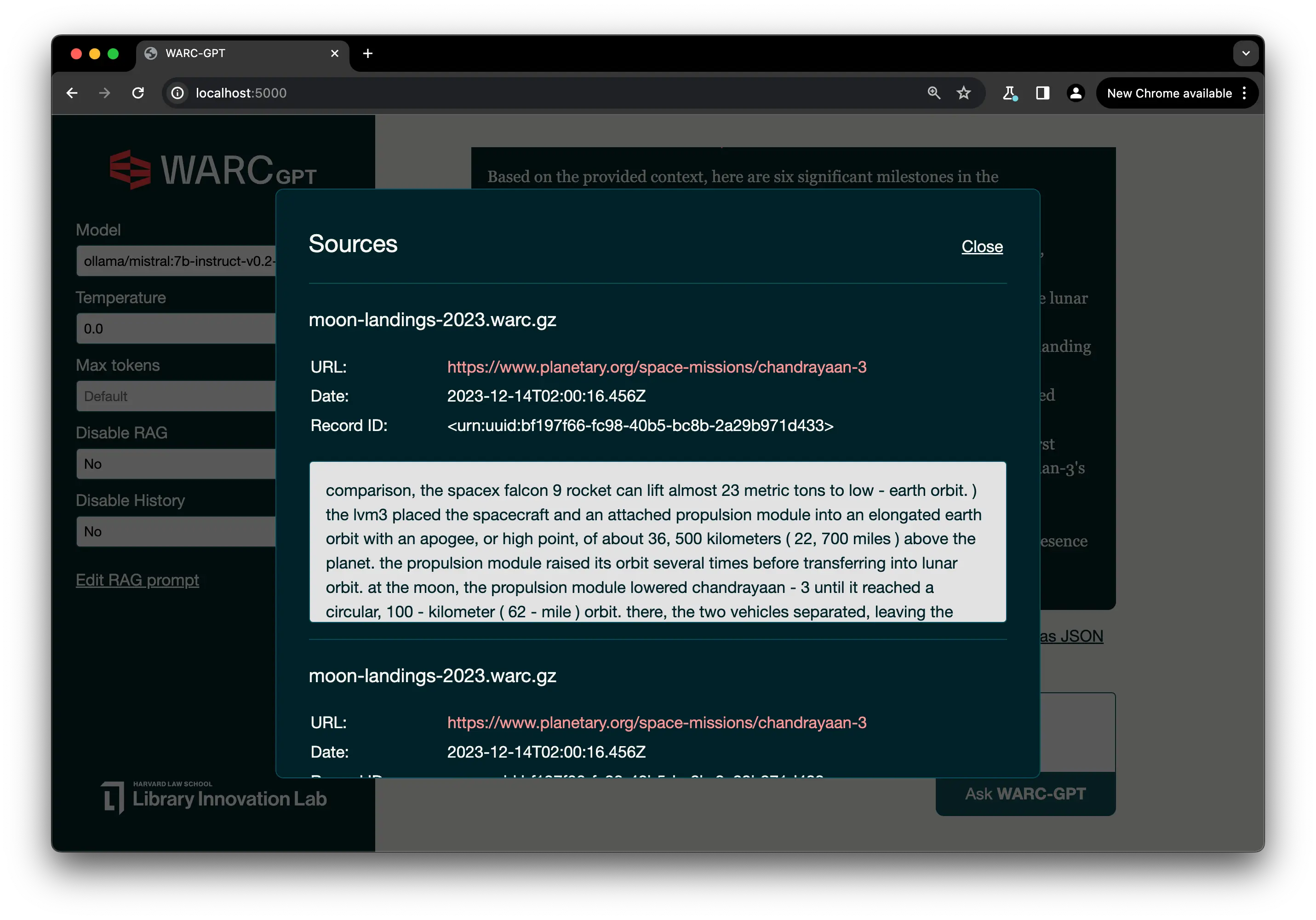
Sources listed from moon-landings-2023.warc.gz:
https://www.cnn.com/2023/12/05/world/chandrayaan-3-lunar-lander-propulsion-module-scn/index.html captured 2023-12-14T01:53:09.589Z
https://www.planetary.org/space-missions/chandrayaan-3 captured 2023-12-14T02:00:16.456Z
https://www.deccanchronicle.com/science/science/051223/isro-brings-back-chandrayaan-3-propulsion-module-to-earths-orbit.html captured 2023-12-14T01:51:55.447Z
In addition, the majority of responses met our criteria for coherence, coverage, consistency, correctness, and clarity. For example, the response to the question “Identify the most important scientific findings of Chandrayaan-3 and why these findings are significant” exemplifies a satisfactory response that meets these evaluation criteria and fulfills the user’s information need.
With RAG: The Chandrayaan-3 mission made several significant scientific findings beyond establishing India as a major player in the space community. Here are some of the most important discoveries and why they matter:
1. Detection of sulphur on the lunar surface: The rover found traces of sulphur, which is crucial for understanding the moon’s formation and evolution since it indicates volcanic activity. This discovery sheds new light on the history of the moon and its geological processes.
2. Temperature difference between the surface and 10 cm below: The rover detected a wide temperature variation between the lunar surface and just 10 cm beneath it, suggesting that lunar regolith is an excellent insulator. This discovery could potentially be used to build space colonies or habitats on the moon, as it can help keep heat, cold, and radiation out.
3. Successful hop experiment by the Vikram lander: The unplanned hop of the Vikram lander demonstrated its capacity for lift-off in a lunar soil environment. This finding is crucial for future space missions since it opens up opportunities for research into bringing samples back from the moon and potential mining or fueling outposts.
4. Measuring the moon’s plasma density: The mission provided valuable insights into the unique lunar environment and its interactions with the cosmos by measuring the moon’s plasma density, which varies as the lunar day progresses. This discovery offers essential knowledge for understanding how space weather impacts the moon and potentially Earth.
5. Valuable data for future lunar exploration: The Chandrayaan-3 mission has provided a wealth of valuable data that will contribute to our understanding of the moon and its potential as a platform for future space exploration missions, including expeditions to other planets and establishing settlements or mining outposts.
These scientific findings are significant because they expand our knowledge of the lunar world and bring us closer to unlocking its potential as a place for human habitation and exploration.
Sources listed from moon-landings-2023.warc.gz:
https://www.indiatoday.in/science/chandrayaan-3/story/chandrayaan-3-how-it-changed-our-understanding-of-the-moon-2445370-2023-10-06- captured 2023-12-14T01:59:51.038Z
As anticipated, our analysis also identified limitations and caveats: some inherent to Retrieval Augmented Generation, some specific to this setup. While we haven’t detected any cases of “hallucination”, the model inconsistently cited its sources within the response at times and, despite being instructed to, failed to indicate in the response itself where the information it used came from. This is the case, for example, in this response to the question “Identify the cause of Luna 25’s crash.”
With RAG: The cause of Luna 25’s crash was a malfunctioning onboard control system that caused the thruster to fail to switch off when the spacecraft reached the planned speed. This resulted in an unplanned thruster burn that lasted for 127 seconds instead of the planned 84 seconds. The failure of the accelerometer unit in the BIUS-L angular velocity measurement block contributed to this issue by preventing the onboard computer from receiving necessary data to timely turn off the spacecraft’s propulsion system.
Sources listed from moon-landings-2023.warc.gz:
https://spacenews.com/russia-blames-luna-25-crash-on-computer-glitch/- captured 2023-12-14T02:15:14.361Z
https://www.themoscowtimes.com/2023/08/20/russias-luna-25-probe-crashes-on-the-moon-roscosmos-a82187- captured 2023-12-14T02:40:17.624Z
https://www.iflscience.com/russias-return-to-the-moon-ends-in-disaster-as-luna-25-crashes-70322- captured 2023-12-14T02:33:51.896Z
https://aviationweek.com/defense-space/space/russias-luna-25-crash-traced-onboard-control-issue- captured 2023-12-14T02:16:05.318Z
While citations weren’t provided consistently within the responses themselves, WARC-GPT provides reference-supported answers by listing the sources that were used to generate the response and the relevant text excerpts that were pulled from the vector store. This enhances the explainability of RAG and provides the user with the source information needed to evaluate the response and verify the information and credibility of the sources provided.
On a few occasions, although relevant information was present in the vector store to help answer the question at hand, WARC-GPT was unable to retrieve helpful context: this indicates limitations in the performance of the ingestion method, embedding model, and distance function we chose. Conversely, in most cases, it appears that the model was able to disregard irrelevant pieces of context it was provided when trying to answer the question.
While some of these issues can likely be partially improved through prompt engineering, or by choosing different sentence-similarity and text-generation models, it is important to remember that this variability is inherent to working with large language models, and that - at the moment - they appear to be a trade-off of the new capabilities they offer when used in such context.
Future directions
We are delighted to share WARC-GPT as an open-source project with the greater web archiving community. We welcome feedback and contributions to this ongoing experiment, which we envision as a collective exploration of artificial intelligence applied to web archiving access and discovery.
This project is in its infancy, and we are looking forward to diving deeper into questions that arose throughout the development of this experiment:
- In the coming months, we will test this technology against larger, real-world collections, and observe whether our small-scale, controlled-environment findings actually scale up.
- WARC-GPT currently focuses on extracting text from HTML and PDF records. We would like a future pipeline to explore multimodal embeddings and text-generation, which would enable us to explore the images present in web archive collections using both natural language and image comparison.
- The “flavor” of RAG that WARC-GPT currently implements is not well-suited to answer questions about the collection itself. A future version could incorporate an ingest-level summarization component, summarizing the contents of WARC records before they are added to the knowledge base, which would allow WARC-GPT to answer questions at a collection level.
Links and resources
Thanks and acknowledgments
We would like to thank our colleagues Rebecca Cremona and Ben Steinberg for their help and support throughout the development of this experiment.
Visuals by Jacob Rhoades.